The Data Surrender Trap: How Enterprises Are Losing Control in the AI Gold Rush—and the Simple Fix
Table of Contents
- Best practices: bring the AI to the data, not the data to the AI
- Open Standards — Give AI Strict Access Without Handing Over the keys
- Databricks: the platform that delivers all four guard-rails
- How the other majors compare—neutral and concise
- Architecture snapshot for engineers and data scientists
- Putting It into Practice - an Up-to-Date Migration & Safe-Sharing Playbook
- Conclusion - Bring AI to Your Data and Future-Proof the Business
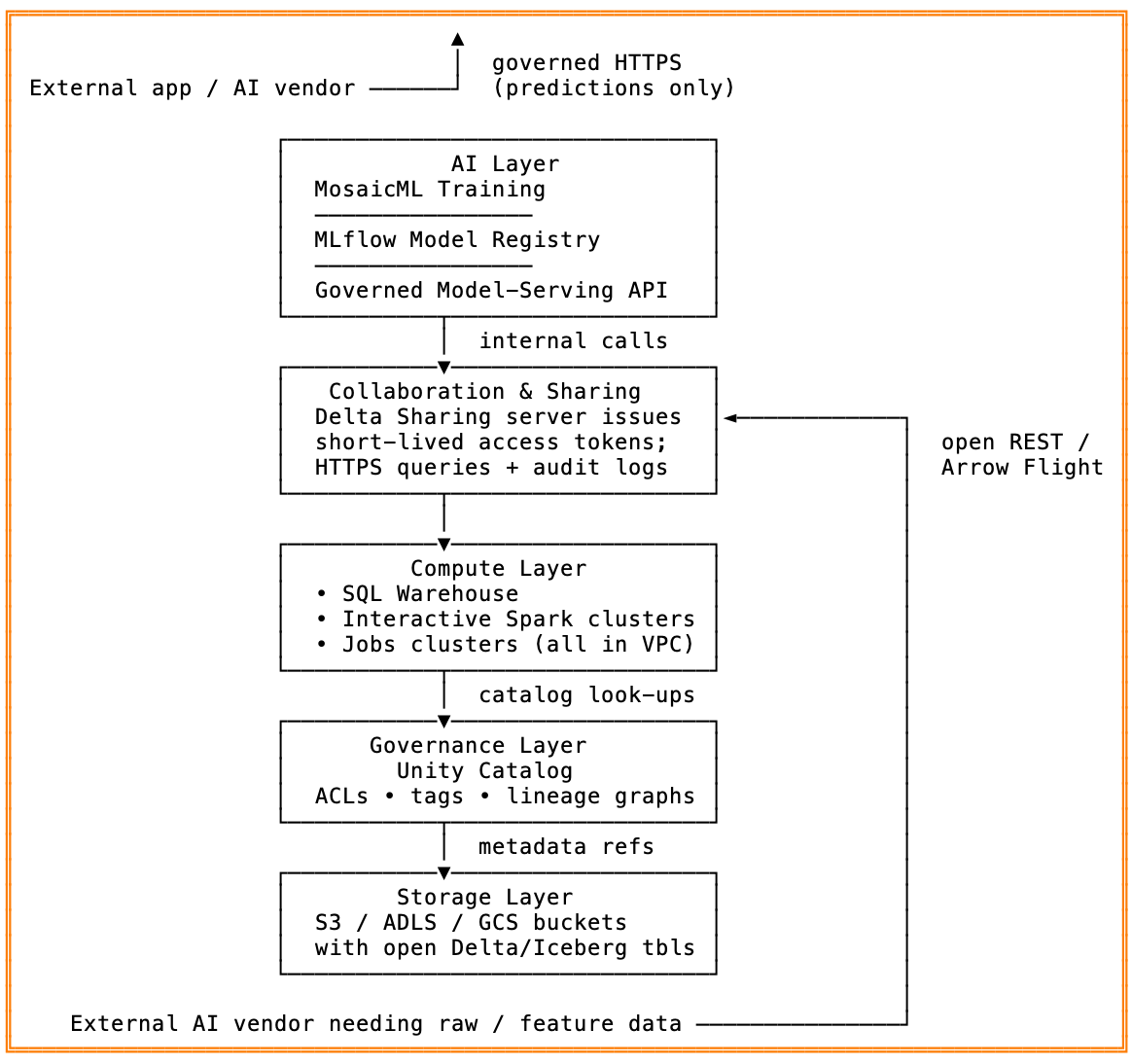
Avoid the data-surrender trap: keep data in-place with open standards and governance, share securely, and bring AI to your data—not the other way around. Generative AI has lit a fire under every product road-map. Faced with “ship it yesterday” pressure, many teams reach for a turnkey vendor: upload data, call an API, launch the feature. It works—until the bill comes due. Handing raw customer data to a third party introduces two long-term headaches: Enterprise architects have converged on four guard-rails for safe, future-proof AI: Platforms that deliver all four let you innovate quickly and satisfy CISOs and regulators. Before we look at any vendor implementation, it helps to know the building-block standards that let you: What this unlocks: With these open standards in place, any platform that respects them can satisfy the four guard-rails—open storage, unified governance, zero-copy sharing, in-platform ML. Databricks’ Lakehouse architecture assembles the pieces in one stack: Because compute clusters run inside your VPC, and storage stays in your buckets, data residency and encryption standards remain under your control. The Lakehouse “brings compute to data,” satisfying the four guard-rails by design. If you are already using Databricks for your data engineering needs, you are in safe hands, leverage these features for the greater good of your data strategy. Key take-aways: All other layers—compute, governance, storage—live inside your VPC / cloud account, so raw data never leaves your perimeter unless you explicitly share it through the Delta Sharing gateway. Each step below tightens control, reduces copies, and shows how to give an external AI vendor only the data they truly need—without falling into the data-surrender trap. Result: engineers still use the notebooks, SQL editors, and BI dashboards they love—but every byte of sensitive data stays in your buckets, under traceable, revocable control. External AI vendors get exactly the slice you permit, for exactly as long as you permit, with a full audit trail to keep everyone honest. The AI race rewards the companies that can move fast without surrendering their crown-jewel data. The way to do that is simple—but non-negotiable: Do those three things and you flip the script: instead of pushing raw tables out to a black-box vendor, you invite algorithms, fine-tuning jobs, and BI tools into a tightly controlled environment. The result is faster experimentation (no week-long data exports), fewer compliance nightmares (every read is logged and revocable), and zero re-platform tax when the next cloud, model, or regulation arrives. In short, bringing AI to your data—under open, governed standards—isn’t just best practice; it’s the only sustainable data strategy for the decade ahead. Adopt it now, and each new AI breakthrough becomes an easy plugin rather than a risky migration. Your teams keep innovating, your security team keeps sleeping, and your customers keep trusting you with their data.
Best practices: bring the AI to the data, not the data to the AI
Guard-rail Why it matters Practical test Open, in-place storage Avoid proprietary traps; support multi-cloud or on-prem moves “If the vendor disappeared tomorrow, could I still read my data in Parquet/Delta/Iceberg?” Unified governance layer Single set of fine-grained permissions, lineage, and audit logs “Can I give a partner read-only access to one column and see every query they run?” Zero-copy sharing Eliminate fragile CSV exports; revoke access instantly “When a collaboration ends, can I cut off data without chasing down replicas?” Integrated model lifecycle Training, registry, and serving inside the governed perimeter “Can I trace every prediction back to its training dataset and code commit?” Open Standards — Give AI Strict Access Without Handing Over the keys
Layer Open standard Why it matters Table formats Apache Iceberg, Delta Lake, Apache Hudi, Parquet Column-oriented, ACID-capable tables that sit in ordinary cloud storage and are readable by engines like Spark, Trino, Flink, etc. Iceberg’s spec is fully open, so any vendor can implement it—preventing lock-in and enabling multi-cloud lakes. Governance / access control Apache Ranger, Open Policy Agent, Unity Catalog, Lakekeeper Centralize table/row/column policies, data masking, and audit logs across dozens of engines and clouds—without embedding rules in every service. Ranger policies even support dynamic row-level filters. Data lineage OpenLineage A vendor-neutral API for emitting and collecting lineage events from Spark, Airflow, dbt, BigQuery, and more. Lets you trace every model back to the exact inputs that produced it. Zero-copy data sharing Delta Sharing (REST), Iceberg REST Catalog, Arrow Flight SQL Instead of emailing CSVs, expose live tables through open protocols. Recipients query directly—Spark, Pandas, BI tools—while you keep full revocation and audit control. Delta Sharing is the first open REST protocol for this purpose; Iceberg’s REST catalog spec and Arrow Flight do the same for metadata and high-speed transport. Databricks: the platform that delivers all four guard-rails
How the other majors compare—neutral and concise
Area Databricks AWS Google Cloud Microsoft Azure Snowflake Open table format Delta Lake (native) Iceberg & Hudi support via Glue BigLake now queries Delta & Iceberg Delta via Synapse Spark Native storage is proprietary; external tables support Iceberg/Delta Central governance Unity Catalog Lake Formation + Glue Catalog Dataplex + BigLake Purview Object tagging, masking policies Zero-copy sharing Open Delta Sharing (any tool) Cross-account Lake Formation permissions; Data Exchange BigQuery authorized views; BigLake metadata Azure Data Share (Azure-only) Snowflake Secure Data Sharing (Snowflake-only) In-platform ML Spark ML + MosaicML + Serving SageMaker (integrated with Lake Formation) Vertex AI (ties to BigQuery/BigLake) Azure ML (ties to Synapse/ADLS) Snowpark ML + Model Registry Control plane Runs in vendor account; data plane in your VPC All in AWS All in Google Cloud All in Azure Managed by Snowflake (still in your cloud region) Architecture snapshot for engineers and data scientists
Putting It into Practice - an Up-to-Date Migration & Safe-Sharing Playbook
Step Action Why / Tips Inventory & classify You can’t apply least-privilege sharing if you don’t know what’s sensitive. Land everything in open, governed tables Open formats + immutable history make later audits and deletions possible. Switch on a unified catalog One policy engine ≫ dozens of per-tool ACLs. Harden the perimeter Keeps “shadow ETL” from copying data out the side door. Safely share with an external AI vendor (zero-copy) Zero-copy protocols let the vendor query live tables without replicating them. Instant revocation closes the door the second you’re done. Move internal ML pipelines onto the platform No more exporting giant CSVs to Jupyter on someone’s laptop. Expose governed model endpoints External apps can call for predictions without direct data access. Automate audits & drift detection Governance-as-code keeps guard-rails from eroding over time. Conclusion - Bring AI to Your Data and Future-Proof the Business